spanner Spanner: Google’s Globally-Distributed Database前言:个人感觉这篇paper组织的逻辑比 Dynamo和GFS 难理解一些,因为时而讲存储引擎层的内容,时而讲存储Service层的内容。笔者按照自己的逻辑重新组织了一下文章,希望能够帮助读者更好的理解Spanner。 推荐阅读:为了更好的体验,请移步至飞书 Spanner. 特征 可扩展的 基于多版本 2022-05-31 #Distributed Storage #NoSQL #Google
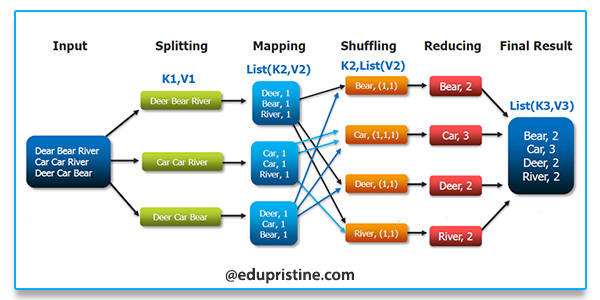
MapReduce MapReduceAbstract: A high-level idea of Map-Reduce Map用户使用Map函数计算出一系列的中间 K-V pairs ReduceReduce 函数在对所有的中间K-V Pairs进行聚合(Merge)操作假设给我十个数组,让我找出每个数组的第五个元素,那么Map函数的作用就是找到每一个数组的第五个元素,Reduce函数就是将每个数组的第五个元素进 2022-05-22 #Google #Distribtued System #Distributed Computing
Twitter 缓存应用分析 Twitter 缓存应用分析 为了更好的阅读体验,请移步至 飞书文档 Abstract TTL 缓存过期时间的设置十分重要。 FIFO 在workload非常大的时候工作得更好(至少和LRU性能差不多,但是理解起来会容易很多)。1 IntroductionIn Memory-Cache: Redis MemCache将研究者的注意力吸引到:缓存命中率,吞吐量和减小延迟。目前的评估方法是存 2022-05-22 #Distributed Storage #Twitter
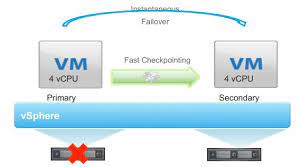
VM-FT VM-FT本文是由VMWare于2010 年提出的一个虚拟机容错解决方案,使用的是一个Primary-BackUp的架构。 推荐阅读:为了更好的阅读体验,请移步至飞书 VM-FT 前言在听取了MIT6.824的课程以及阅读了VM-FT的paper之后,笔者个人感觉要让VM级别的应用实现Fault Tolerance的难度会比DB (In-Memory / Disk) 级别的应用大不少,主 2022-05-22 #Distributed System #Distributed Storage
Partition Partition的目标是用来提升读写的请求吞吐的,每一个Partition保留的整个数据集的一部分,针对不同数据的请求会被路由到不同的Partition中 MongoDB,ES,SolrCloud中的Shard HBase中的 Region BigTable中的 Tablet Cassandra和Riak中的 VNode Couchbase中的 vBucket1 Partition & 2022-05-22 #Distributed Storage #DDIA
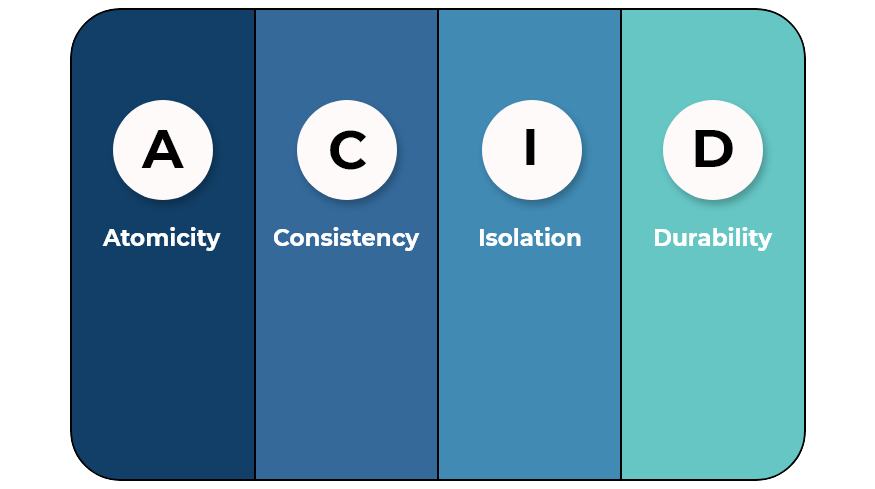
Transaction Transaction几乎所有的关系型数据库和部分NoSQL能够提供事务支持,早在1975年IBM提出的第一个SQL系统System-R中,介绍了事务的概念。虽然在过去的40年中,事务的实现方式改变了许多,但是其基本的思想与40年前的System-R几乎是一致的 ,在MySQL,PostgreSQL, Oracle, SQL Server中 事务的实现原理几乎是与System-R相同的。 推荐阅读 2022-05-22 #Distributed Storage #DDIA
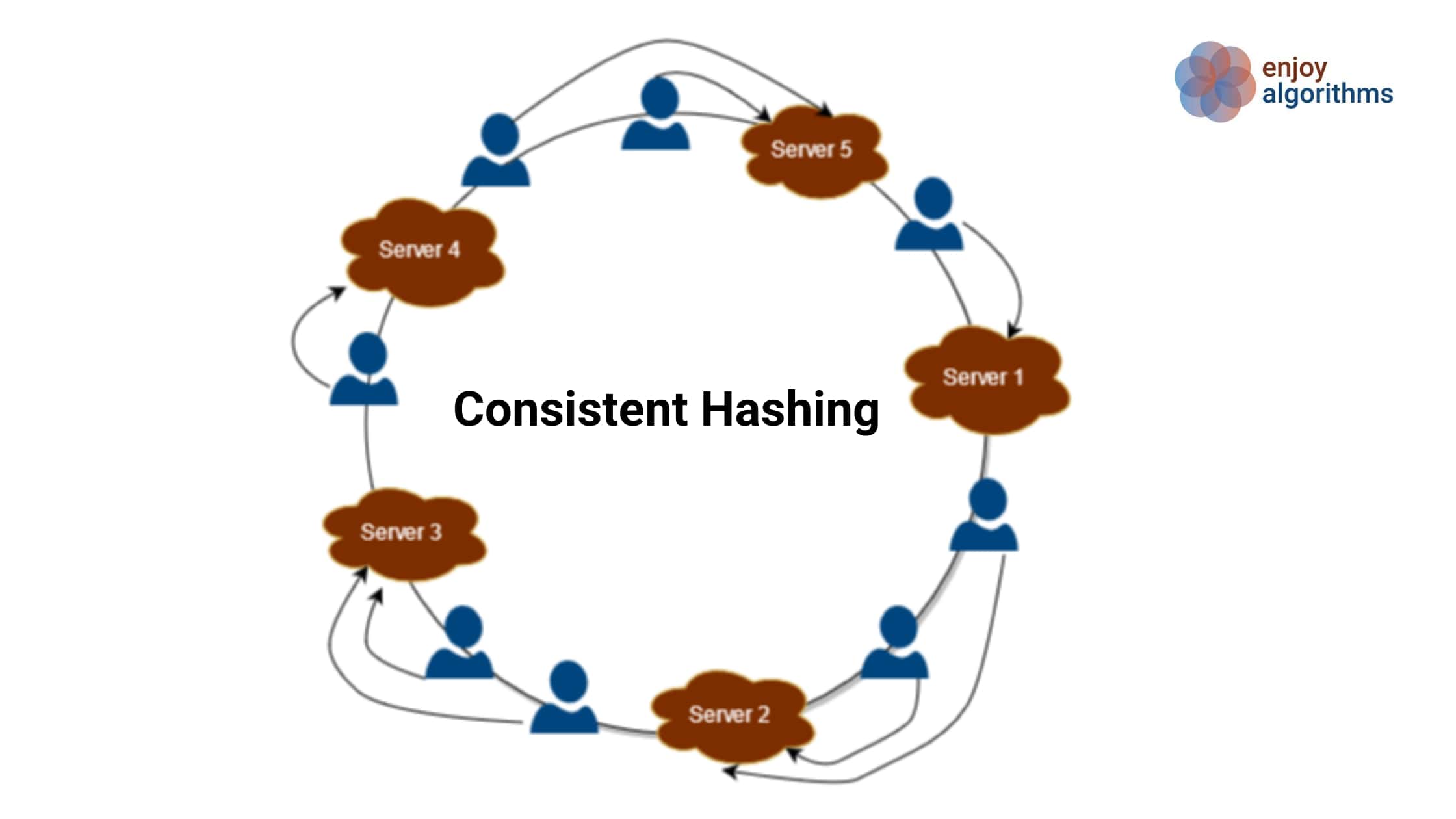
Dynamo Dynamo: Amazon’s High Available KV Store DynamoDB是Amazon平台上构建的 “always on” availability 级别的NoSQL数据库,并且能做到无缝扩展 (high-scalability)。为了实现这个级别的可用性,它在某些故障场景中将不可避免的牺牲一致性。最重要的两个核心点:High-Availability & Sca 2022-05-22 #Distributed Storage #NoSQL #Amazon
GFS Google File System 分布式文件系统,弱一致性模型 (Relaxed Consistency); 谷歌三驾马车之一,与MapReduce和BigTable开启了新的大数据时代,引领工业界向NoSQL发展; 推荐阅读:为了更好的体验,推荐移步至飞书文档。 GFS FAQ。 Intro单机系统的存储容量始终是有限的,随着数据量不断增大,如果只对单台机器进行scale up也会逐渐达 2022-05-22 #Distributed Storage #Google #File System