complete_system

The requirement for auto complete system should be:
Lightening fast reads. When users type in keywords, the service responds in a very fast way. Facebook found that an autocomplete needs to return suggestions in less than 100 ms.
Relavancy of suggestions: should return the most frequent query result from the database for one keyword.
Understand the problem and Establish design scope
Requirement Detail: Search Top-5 frequent suggestions for a keyword
User Scope: Assume there are 10 million DAU
No spell check
One of the important features of this system is that the suggested result is not user-specific. While on Facebook there is a lot of user-specific data such as feed.
Back-of-the envelope-estimation
Traffic: Assume that on average, one user will search 10 times a day and in each query there are 20 characters
QPS: 10,000,000 * 10 * 20 / (24 * 60 * 60) = 24000
Peak QPS: 48000
Storage: each query contains 20 characters, so the size of a query is 20 bytes. It generates (10, 000, 000 * 10 * 20) bytes per day and assumes that the new query takes up 20% of the total queries.
So the storage space increases 0.4 GB per day.
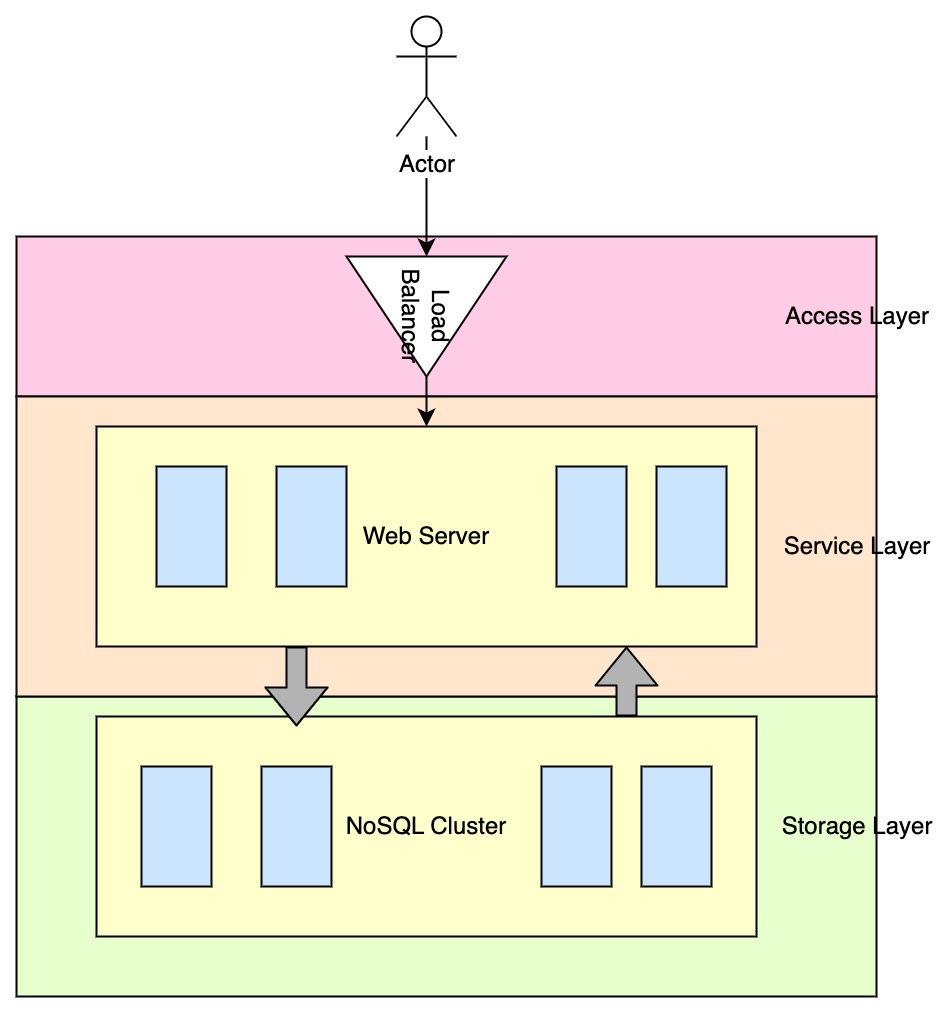
High Level Design
The client sends a request to the API gateway. The load balancer will choose one web server to handle the query request.
The Web Server will first compute the top-5 frequent keyword queries from the query history and then increase the querying keywork count by 1.
The storage layer could be NoSQL because the storage model does not need relational information and the query can be tolerated for eventually consistency. Availability weighs more in this scenario. Because we always expect the search server to respond to the user query and if the suggestion is not the up-to-date order, it will be acceptable.
System Architechture
You should clarify if the search service is for an active online search application like Twitter or an offline search like Google Search.
The former one may require you to update the trie immediately, the latter one may tolerate the result is not up to date.
The update can not be simply done with incrby, because you must maintain the trie tree as well. It should not update the words but should also update the prefix. It would be too time-consuming if you wanted to do this in real time.
Dive into Deep
Trie Tree
For the auto complete problem, it is easy to recall that Trie tree fit the scenario well. In a view, the data structure would be like:
1 | |
A picture from Alex Xu’s book:
Query Process: Query the word is to query the trie tree. If we find prefix in the trie tree, then we have to find all the children under the node and sort them within a heap to generate the top-5 results.
The total time consists of three parts: O(L) + O(N) + O(KlogK)
The first part is raised by the length of type-in keyword
The second part is all the completions in the Trie leafnodes
The third part is sorting out raw results
However, the process is really time-consuming, assume that the user only enters ‘s’ and you have to traverse all the leaf nodes starting with ‘s’.
Quick Calculation:
The time complexity is O(N) for querying the suggestion where N is the total number of keywords (completions) in the Trie.
This is really a bottleneck of the system which increases the responding time.
There are some optimization we can do to remove the above time bottleneck.
Remove O(N)
One possible way to improve the query process is to cache the top-5 result for a node. In Google Search scenario, the top-5 result can read stale data for the reason that the suggestion can be a little bit outdated. While in the Twitter scenario, the top-5 results should be as accurate as possible.
Trade-offs
For the keyword ‘bee’, we have to store it multiple times in the node (‘b’, ‘be’, ‘bee’). But since speed of reads was our priority, we were happy to make these trade offs****.
Remove O(L)
If we can limit the length of keywords, like we define the max length of L as 50 chars. For searching more than 50 chars, we can simple block the auto complete service.
This is what Google Search does. You can try to paste different things into the search bar. And you may find that if you type in a sentence which is too long, there won’t be any suggestions.
Remove O(KlogK)
To most of the auto- complete suggestions, it only requires us to generate the top5 or top10 related results. So the K can be regarded as a constant and O(KlogK) is nothing more than O(1).
How to Store Trie Tree in the DB
Stored in Document DB
From Alex Xu’s book, the idea is to take a snapshot of the DB weekly and store the data into Document NoSQL like MongoDB.
Stored in KV Store
| Key | Value |
|---|---|
| c | [car: 30, cat:20, curry:10] |
| ca | [car:30, cat:20, canada:10] |
This gives us a few advantages, such that we can access any prefix in O(1) time. This eliminates the tree traverse process in the memory. But it also increases the storage space because it loses the conventional trie’s ability to share common prefixes. A hashmap also requires more space to store the meta data such as load factor and map size.
But again, we were more than willing to trade space for speed of reads.
We can use Redis / Abase to store the trie data. To store the completion data, we could use Redis list or Redis Zset.
| Redis List | Redis Zset | |
|---|---|---|
| Performance | Search for O(1)Update for O(K) | Search and Update for O(logK) |
| Operation Complexity | Need to take care of sorting and de-duping. When updating, it requires us to take two round trips with Redis, load all the lists and increase and insert the new entry in-place. | Not require to take care the sorting and deduping logic. The ZSET will maintain the order and uniqueness through skiplists. |
| Commands | LRANGE: Load all the list LREM: Remove the updated entryLINSERT: Insert new entry into the list | ZRANGE: for search ZINCRYBY: for update |
Cache by Redis and Persist By MongoDB
MongoDB is a key document NoSQL which fits well with the Redis KV model. Having similar models of abstraction among data stores is convenient, because it makes the persistence process easier to reason about.
For the cache miss handling, we can implement Cache Aside Pattern. Note that the logic for searching in the event of cache miss only happens quite a few times, and when there’s cache miss it can quickly load the data into Redis so that the next query can hit the cache. Thus, the slower and more complicated logic for searching persistent stores only happens in a relatively small number of cases.
How to update the Trie Tree
The query service can store the query history and periodically generates the analysis log based on the historical data. With this analysis log, we can build the Trie once and use it for a long time.
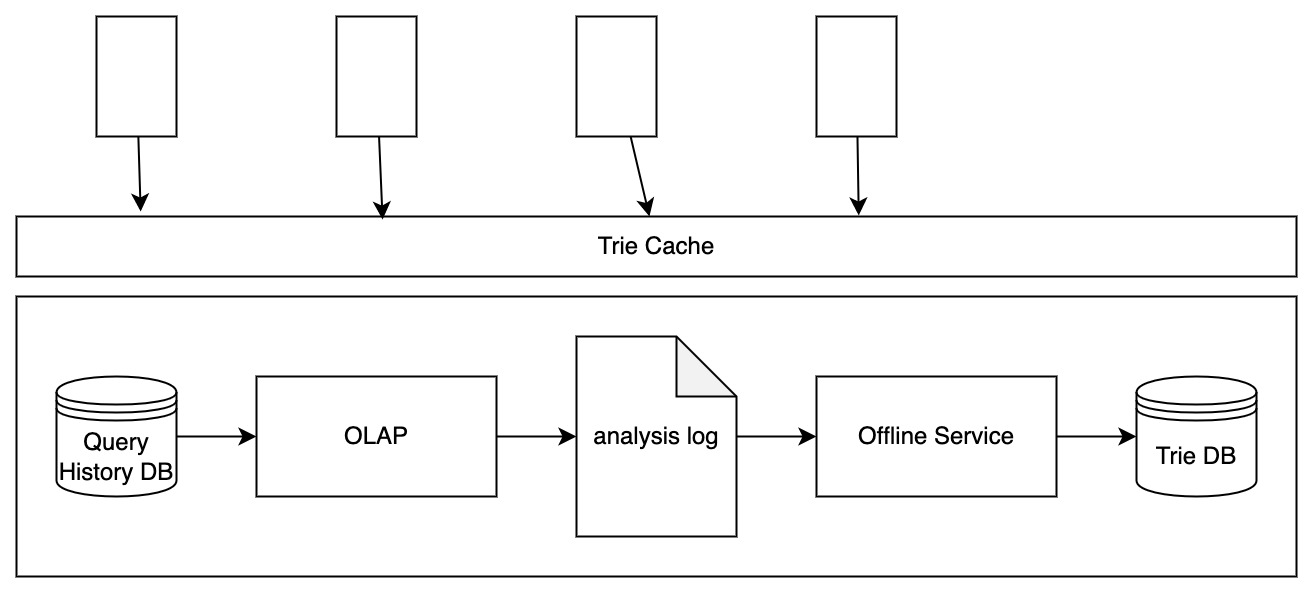
But note that this mechanism is only feasible for the Google Search scenario where the auto complete suggestion does not require realtime update. For the Twitter auto complete scenario, you may want to figure out some faster way to update the Trie store.
How to partition the data efficiently
The words starting with ‘s’ are more than the words starting with ‘x’ and this might cause sharding inbalance. To mitigate the problem of unevenly distributed characters. We may introduce a shard manager to do the routing.
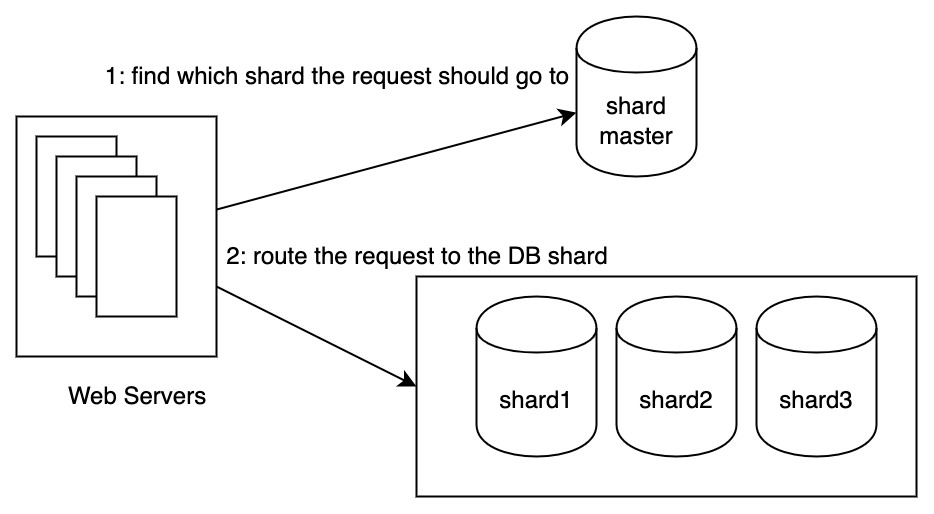
Wrap Up
Some questions to think about:
- How do you extend your design to support multi-language?
Hint: Unicode
- What if we want to do auto-complete based on different countries?
- How can we support real-time search queries?
Update immediately